Перелік коротких описів
Штучний інтелект і машинне навчання
« Повернутися до практикування
Підрозділи
- Штучний інтелект і машинне навчання
- Штучний інтелект
- Úvod do umělé inteligence
- Визначення штучного інтелекту
- Застосування та можливості штучного інтелекту
- Штучний інтелект: реальність і вигадка
- Історія штучного інтелекту
- Штучний інтелект: поняття
- Застосування штучного інтелекту
- Обробка природної мови
- Робототехніка
- Комп'ютерний зір
- Методи штучного інтелекту
- Завдання та методи штучного інтелекту
- Перегляд простору станів
- Виконання умов
- Оптимізація
- Машинне навчання
- Упередженість машинного навчання
- Машинне навчання: поняття
- Методи машинного навчання
- Лінійна регресія
Штучний інтелект і машинне навчання
Штучний інтелект (ШІ, англ. AI – artificial intelligence) — це галузь інформатики, яка займається створенням програм для вирішення складних проблем, які зазвичай потребують людського інтелекту.
- Загальний огляд надається в розділі основи штучного інтелекту. У ньому ми маємо справу, наприклад, з тим, що таке штучний інтелект, а чим він не є, що він може, а що не може, що є реальністю, а що вигадкою.
- У другому розділі представлено кілька застосунків штучного інтелекту: обробка природної мови, комп’ютерне бачення та робототехніка.
- Третій розділ присвячено методам штучного інтелекту – пошук у просторі станів, виконання умов та методи оптимізації.
Потім ми присвячуємо два розділи машинному навчанню – підгалузі штучного інтелекту, яка займається створенням програм, які навчаються на даних.
- Розділ основи машинного навчання описує принцип і процедуру машинного навчання, а також розглядає ризик спотворення (зміщення).
- В останньому розділі більш детально розглядаються методи машинного навчання, такі як: лінійна регресія, дерева рішень і нейронні мережі.
Штучний інтелект

Штучний інтелект часто називають абревіатурою AI (від англ. artificial intelligence). Це галузь інформатики, яка займається створенням інтелектуальних машин, здатних виконувати завдання, які зазвичай потребують людського інтелекту. Штучний інтелект, наприклад, розуміє мови, розпізнає зображення і вирішує складні завдання, як-от, водіння автомобіля.
Сфера штучного інтелекту є складною та включає багато передових методів. У рамах Знаємо інформатику ми пропонуємо базовий огляд теми, розділений таким чином:
- Поняття – огляд основних понять, що використовуються у сфері штучного інтелекту
- Історія штучного інтелекту – огляд поступового розвитку штучного інтелекту, основні віхи
- Застосування та можливості штучного інтелекту – базовий огляд того, що штучний інтелект може, а чого не може робити
- Штучний інтелект: реальність і вигадка – різниця між тим, що працює в реальності, і тим, що можливе лише в науковій фантастиці.
Окрема велика тема присвячена машинному навчанню, яке є галуззю штучного інтелекту, яка значно розвинулася за останні роки й зараз відіграє важливу роль у багатьох програмах.
ВгоруÚvod do umělé inteligence
Штучний інтелект (скорочено ШІ від англійського Artificial Intelligence) — це галузь інформатики, яка займається створенням програм для вирішення складних задач, які в іншому випадку вимагали б людського інтелекту. Штучний інтелект використовується не лише роботами, а й програмами, які грають у шахи, розпізнають рослини на фотографії, перекладають текст іноземною мовою, рекомендують музику або керують автомобілем.
Що є ШІ, а що ні
Інтелектуальна поведінка включає здатність сприймати навколишнє середовище, розуміти мову, робити висновки, планувати, навчатися, адаптуватися до змінних ситуацій та приймати самостійні рішення. Однак, щоб вважатися штучним інтелектом, програмі не обов’язково мати всі ці характеристики. Наприклад, розв’язувач судоку значною мірою використовує логічне мишлення, але йому не обов’язково розуміти мову чи адаптуватися до змінних ситуацій.
Зображення штучного інтелекту в книгах і фільмах не відповідає сучасним технологіям або очікуваному сценарію розвитку. Сучасний штучний інтелект не є свідомим і не відчуває емоцій. Поки що не існує загального штучного інтелекту, який би міг вирішити будь-яку проблему хоча б так само добре, як людина.
Як працює ШІ
Штучний інтелект — це не магія, а складні алгоритми. Для досягнення інтелектуальної поведінки використовуються різні методи, такі як систематичне тестування можливостей, логічний висновок та машинне навчання. Не весь штучний інтелект використовує машинне навчання. Наприклад, розв’язувач судоку може обійтися комбінацією логічних висновків та систематичного тестування можливостей.
Машинне навчання базується на навчанні з великої кількості прикладів (до мільярдів зображень і трильйонів слів). Замість того, щоб писати програму, яка крок за кроком описує рішення, ми створюємо програму, яка сама вивчає рішення. Програмі недостатньо просто запам’ятовувати приклади, які ми їй показуємо. Щоб мати змогу вирішувати нові ситуації, вона повинна виводити загальні закономірності з наданих прикладів.
Нейронні мережі та глибоке навчання
Існує низка алгоритмів для машинного навчання. Останнім часом особливої популярності набули нейронні мережі, вільно натхненні зв’язками між нейронами в мозку. Замість власне нейронів мережа використовує прості функції, але оскільки вона містить їх мільйони, загальна функція є складною.
Глибоке навчання стосується навчання великих («глибоких») нейронних мереж, що раніше було неможливо. Сьогодні таке навчання можливе не лише завдяки розумнішим алгоритмам, але й особливо завдяки значному збільшенню обчислювальної потужності та доступних прикладів для навчання.
Історичний розвиток
Дослідження штучного інтелекту розпочалися в середині 20 століття, але значне промислове використання почалося лише у 21 столітті. Важливим фактором було довгострокове збільшення обчислювальної потужності, що дозволило машинне навчання на основі великих обсягів даних. Приблизно у 2020 році було розроблено генеративний ШІ, тобто штучний інтелект, який створює новий контент (зображення, текст, звук).
Переваги та ризики ШІ
Штучний інтелект спрощує повсякденну діяльність (переклад тексту, пошук інформації), дозволяє персоналізування (рекомендування музики або фізичних вправ), зменшує бар’єри (створення субтитрів для глухих) та пришвидшує дослідження (розробку нових ліків).
Однак використання штучного інтелекту також несе ризики. ШІ не є безпомилковим і не є об’єктивним, оскільки він навчається з даних з Інтернету, які містять помилки та упередження. Він може видавати хибне твердження за факт (так звані галюцинації), тому доцільно перевіряти інформацію від ШІ. ШІ, що використовується для прийняття рішень (наприклад, відбору кандидатів на роботу), може використовувати упередження з даних, дискримінувати певні групи та таким чином поглиблювати нерівність. Генеративний ШІ сприяє створенню навмисних фейків, які виглядають правдоподібно та намагаються маніпулювати громадською думкою (так звані діпфейки).
ВгоруВизначення штучного інтелекту
Штучний інтелект (ШІ, англ. AI – artificial intelligence) належить до програм, які вирішують складні проблеми (як-от, гра в шахи або керування автомобілем), а також галузі інформатики, яка займається створенням цих програм. Штучний інтелект – це не просто роботи, частіше це комп’ютерна програма без фізичної форми. Штучний інтелект використовується всюди, де є складні проблеми, наприклад в обробці природної мови, робототехніці та комп’ютерному зорі.
Визначення штучного інтелекту
Немає єдиного визначення штучного інтелекту. Іноді програми, які поводяться як люди, вважаються штучним інтелектом, але це обмежує, оскільки люди часто не поводяться розумно, роблять помилки та не можуть вирішити деякі складні проблеми. Тому доцільніше розглядати програми, які поводяться розумно (раціонально), як штучний інтелект. Розумна поведінка означає, що програма намагається максимізувати очікувану корисність (як-от, імовірність перемоги в шахах).
Тест Тюрінга
У середині 20-го століття Алан Тюрінг запропонував наразі дуже відомий тест для розпізнавання штучного інтелекту: якщо ми не можемо відрізнити письмову комунікацію: чи говоримо ми з людиною, чи з програмою, то ми можемо вважати дану програму штучним інтелектом. Для проходження тесту Тюрінга штучний інтелект як програма, яка поводиться як людина, не має відповідати надто швидко та мусить навмисно робити помилки, які б зробила людина (як-от, множення на великі числа).
ШІ ефект
Штучний інтелект вирішує складні проблеми – проблеми, для вирішення яких донедавна потрібен був людський інтелект. Як тільки ми звикаємо до того, що комп’ютери можуть вирішити ту чи іншу проблему, ми перестаємо сприймати її як складну, а програму, яка її вирішує, перестаємо сприймати як штучний інтелект. Ця постійна зміна того, що ми вважаємо штучним інтелектом, називається ефектом ШІ.
Вузький чи загальний штучний інтелект
Вузький штучний інтелект може вирішити лише певний спеціалізований тип задач (як-от, гра в шахи, розпізнавання облич на фотографіях), тоді як загальний штучний інтелект (AGI від англ. artificial general intelligence) може вирішити будь-яку проблему так само, як і людина. Загального штучного інтелекту ще не існує. (Терміни «слабкий і сильний ШІ» також іноді використовуються для цього розрізнення, але при точному використанні вони мають дещо інше значення — розрізняють, чи має ШІ власну свідомість.)
Споріднені терміни
Штучний інтелект, машинне навчання та нейронна мережа не є синонімами. Штучний інтелект часто використовує машинне навчання (навчання на основі даних або досвіду), але є також багато методів штучного інтелекту, які не використовують машинне навчання. Нейронна мережа є лише однією з багатьох моделей, які використовуються в машинному навчанні.
ВгоруЗастосування та можливості штучного інтелекту
Типові сфери застосування штучного інтелекту включають:
- робототехніку (робот-пилосос, промислові роботи, самокеровані автомобілі),
- системи рекомендацій (алгоритми рекомендацій фільмів, книг),
- обробку природної мови (переклад між мовами, пошук інформації, виявлення спаму),
- розклад та планування (планування виробництва на заводі),
- обробку зображень (розпізнавання людей або номерних знаків на фото),
- комп’ютерні ігри (керування поведінкою неігрових персонажів (NPC)).
Штучний інтелект має застосування в основному у сферах, де використовуються повторювані дії, як-от, робота виробничих ліній, керування машинами, основні адміністративні завдання.
Штучний інтелект поки що не має здібностей, які вимагають більш складних ручних операцій (наприклад, стрижка волосся), координації різних дій (як-от, ремонт квартири), соціальних навичок та емпатії (наприклад, охорона здоров’я) або креативності та самостійного формулювання цілей (як-от, дослідження).
ВгоруШтучний інтелект: реальність і вигадка
Штучний інтелект також часто зустрічається у творах мистецтва (книгах, фільмах, виставах). Однак його зображення в художній літературі часто не відповідає дійсності, і тому корисно вміти розрізняти, що є реальністю, а що вигадкою.
Приклади відомих вигаданих роботів і програм:
- Голем, Франкенштейн: Штучні машини, здатні мислити, з легенд або книг, які з’явились раніше слова “робот”.
- Роботи у виставі R.U.R. Карела Чапека (перше вживання слова “робот”).
- HAL 9000: Програма управління космічним кораблем з фільму «2001: Космічна одіссея». Відомий тим, що намагався вбити космонавтів, щоб виконати місію.
- Марвін: Робот-параноїк із серії книг Автостопом по Галактиці.
- KITT: Розумний автомобіль із серіалу Knight Rider.
- Номер 5: Робот, який прийшов до свідомості після удару блискавки.
- R2D2, C-3PO, BB8: Роботи із серії фільмів Зоряні війни.
- SkyNet: Суперрозум, налаштований на знищення людства у фільмах про Термінатора.
- Бендер: Людиноподібний робот із серіалу Футурама.
- ВАЛЛ-І: Робот (збирач сміття) з однойменного фільму.
Три закони робототехніки Айзека Азімова, які вперше з’явились у серії оповідань, також є вигаданими. Однак ці фіктивні закони стали основою для багатьох дискусій про моральні проблеми розвитку роботів.
Приклади відомих справжніх ботів і програм:
- Deep Blue: Шахова програма, перемогла гросмейстера Гаррі Каспарова.
- IBM Watson: Програма, здатна відповідати на запитання.
- AlphaGo: Перша програма, яка перемогла гросмейстера гри в Го.
- Eliza: Перша відома чат-програма (1966).
- ChatGPT: Сучасна (2022) чат-програма.
- Alexa, Siri: Віртуальні помічники.
- ASIMO, Pepper: Гуманоїдні роботи.
Історія штучного інтелекту
До 1950 року
- Карел Чапек написав п’єсу R.U.R, де вперше вжито слово «робот» (1920).
- Перші комп’ютери, які використовувалися головним чином для обчислень під час Другої світової війни (наприклад, для дешифрування).
1950-1960
- Алан Тюрінг пропонує тест машинного інтелекту (тест Тюрінга), де людина повинна розпізнати, чи спілкується вона з комп’ютером чи людиною.
- Основи штучного інтелекту як науки, перші принципи алгоритмів штучного інтелекту.
1960-1970
- Перші чат-програми (як-от, Eliza).
- Перші програми, які грають у настільні ігри (наприклад, шашки чи хрестики-нулики) на аматорському рівні.
- Перші самохідні роботи (як-от, Shakey).
- Основи обробки природної мови.
- Основи розпізнавання зображень.
1970-1990
- Зниження початкового оптимізму щодо штучного інтелекту, зменшення фінансування (період, який називають «зимою АІ»).
1990-2000
- Інтернет та веб-розробки, використання штучного інтелекту для пошуку.
- Програма Deep Blue перемогла гросмейстера у партії в шахи.
- Безпілотні автомобілі, які можна використовувати в обмежених умовах і під контролем.
2000-2010
- IBM Watson перемогла людей на Jeopardy! (гра-вікторина).
- Розробка рекомендаційних систем (Netflix, YouTube, Amazon).
- Безпілотні автомобілі, які долають довгі позашляхові маршрути або реалістичний трафік (наразі без значного самостійного використання у звичайному русі).
2010-2020
- Швидкий розвиток галузі «глибокого навчання» (використання нейронних мереж, навчених на дуже великих даних).
- Практична обробка мови (як-от, віртуальні помічники Siri, Alexa).
- Значне покращення в розпізнаванні зображень (наприклад, облич на фотографіях).
- Перемога штучного інтелекту над людьми в інших іграх: го, покер. Можливість грати у прості комп’ютерні ігри («аркади»), засновані виключно на візуальному введенні.
- Безпілотні автомобілі, які можна використовувати у звичайному русі.
2020-2030
- Розвиток генеративного штучного інтелекту: створення зображень, генерація тексту, програми для спілкування.
Штучний інтелект: поняття
Вступна примітка. Точне значення наведених нижче термінів часто є складним і не зовсім зрозумілим. Наші короткі описи намагаються передати лише їх суть.
Методи, прийоми, підходи
| поняття | опис |
|---|---|
| штучний інтелект | програми, здатні виконувати завдання, що вимагають інтелекту |
| вузький штучний інтелект (слабкий АІ) | може розв’язати лише певний спеціалізований тип задач (наприклад, гра у шахи, розпізнавання облич на фотографіях) |
| загальний штучний інтелект (сильний АІ) | штучний інтелект, який може розв’язати будь-яку задачу (пограти в яку завгодно настільну гру, виконати нові операції з фотографіями на основі словесного опису тощо) |
| генеративний штучний інтелект | штучний інтелект, здатний створювати новий контент (зображення, текст, звук) |
| зрозумілий штучний інтелект | системи та моделі, які можуть пояснити, чому поводяться саме так |
| машинне навчання | методи, засновані на автоматизованому навчанні з даних; не всі підходи штучного інтелекту використовують машинне навчання (наприклад, АІ для судоку не використовує машинне навчання з даних) |
| нейронна мережа | техніка машинного навчання, дещо натхненна тим, як працює біологічний мозок |
| глибоке навчання | підтип нейронних мереж, що використовує ієрархічне представлення функцій |
| генетичний алгоритм | підхід, заснований на біологічних процесах успадкування / еволюційних механізмах |
| посилене навчання | підгалузь машинного навчання, експериментального навчання на основі винагород і покарань |
Області застосування
| поняття | опис |
|---|---|
| робототехніка | розвиток машин, які переміщуються у просторі |
| людиноподібний робот | його конструкція та зовнішній вигляд нагадують людину (також називають андроїдом, особливо якщо його поверхня нагадує шкіру) |
| автономний робот | робот, який працює самостійно |
| обробка природної мови | машинна обробка звичайних людських мов (наприклад, чеської, англійської, німецької) |
| чат-програма | програма, яка здатна спілкуватися з людиною (переважно у письмовій формі) |
| комп’ютерний зір | отримання інформації з даних зображення |
| розпізнавання мови | автоматичне перетворення мови в текст |
| синтез мовлення | штучне створення людського мовлення |
| система рекомендацій | система, яка надає персоналізовані рекомендації для користувача (наприклад, фільм, який може сподобатися користувачеві) |
Застосування штучного інтелекту
Штучний інтелект і машинне навчання знаходять застосування у багатьох сферах прикладної інформатики. На Знаємо це ви знайдете базовий огляд таких тем:
- обробка природної мови: виявлення спаму, відповіді на запитання
- робототехніка: робот-пилосос, безпілотні автомобілі
- комп’ютерний зір: розпізнавання людей або номерних знаків на фото
Ви можете практикувати, що штучний інтелект може, а що ні в рамах теми Застосування та можливості штучного інтелекту.
ВгоруОбробка природної мови
Обробка природної мови (англ. natural language processing) — це галузь на межі між інформатикою (зокрема, штучним інтелектом) і лінгвістикою, яка досліджує аналіз і генерацію письмового чи усного слова. Завдання обробки природної мови включають:
- класифікація тексту (виявлення спаму, визначення жанру, визначення авторства)
- кластеризація тексту (створення груп схожих новин або пов’язаних судових справ)
- вичитка тексту (перевірка орфографії, перевірка граматики)
- генерація тексту (відповіді на запитання, узагальнення тексту, машинний переклад)
- розпізнавання мовлення (мовлення → текст) і синтез мовлення (текст → мовлення)
- опис зображень (зображення → текст) та створення зображень (текст → зображення)
Підхід за правилами
Раніше для цих завдань використовувалися підходи на основі правил, намагаючись зафіксувати правила даної мови (як-от, час дієслів). Аналіз тексту поділявся на кілька рівнів (рівнів мови): 1) морфологія (побудова слів), 2) синтаксис (композиція речень), 3) семантика (значення речень) і 4) прагматика (використання речень у контексті). Однак виявити природну мову за допомогою правил виявилося складно.
Ускладнення обробки природної мови
Кожне правило має ряд винятків, і тексти природною мовою містять друкарські та інші помилки, які також потрібно моделювати, якщо ми хочемо зрозуміти текст. Іншою складністю є багатозначність на багатьох рівнях: омоніми, тобто слова з кількома можливими значеннями (ключ, рукав, коса), речення з кількома можливими значеннями («Їжте швидко остигаючий суп»), займенники, що стосуються раніше згаданих об’єктів (анафори) та інші посилання на інші частини тексту або навіть поза ним (я, зараз). Значення речень не завжди можна визначити зі значення окремих слів, як-от, при використанні ідіом, метафор і метонімій.
Машинне навчання
Наразі обробка природної мови вирішується майже виключно за допомогою машинного навчання, що дає значно кращі результати, ніж підходи, засновані на правилах. Для навчання використовуються великі колекції текстових документів, відомі як корпуси. Корпус містить, наприклад, оцифровані книги, онлайн-енциклопедії (Wikipedia), іноді навіть тексти з більшості доступних вебсайтів і, таким чином, може містити мільярди слів.
Результатом машинного навчання є модель мови, яка оцінює ймовірність наступного слова в аналізованому тексті. Таку модель потім можна використовувати для створення тексту в чат-ботах (шляхом повторного вибору одного з імовірних інших слів) або вибору найбільш вірогідного речення з декількох (це корисно, наприклад, у розпізнаванні мовлення чи машинному перекладі). Мовні моделі, реалізовані за допомогою великих нейронних мереж із мільярдами параметрів (які встановлюються під час навчання), називаються великими мовними моделями (англ. large language models, LLM).
ChatGPT
Прикладом великої мовної моделі є GPT, генеративний попередньо навчений трансформатор. Це генеративна модель, оскільки вона дозволяє генерувати текст. Вона попередньо навчена на великому наборі даних текстів з більшості доступних вебсайтів. Трансформатор (англ. transformer) — це популярний тип нейронної мережі, що дозволяє ефективно навчатися на таких великих даних. У свою чергу ChatGPT — це назва певної програми (чат-бота), яка використовує цю велику мовну модель у своїй основі.
Представлення тексту
Основною одиницею під час роботи з текстом є токени, які зазвичай є або відомими словами, або частинами невідомих слів. В одній мові існує кілька десятків тисяч можливих лексем. Поділ тексту на токени називається токенізація. Для деяких застосувань корисно перетворювати слова в їх основну форму, так звану лему (яблука → яблуко, будемо → бути).
Окремі слова часто представляють за допомогою так званих вбудованих слів як вектори дійсних чисел у багатовимірному просторі. У цьому просторі слова подібного значення знаходяться поруч.
Тоді групи слів можна представити або як набір, тобто незалежно від порядку (англійською bag of words), або зі збереженням порядку у вигляді так званих n-грам (наприклад, біграми — це пари послідовних слів).
ВгоруРобототехніка
Робототехніка займається розробкою роботів, тобто машин, які пересуваються у просторі, сприймають оточення та приймають рішення на основі свого стану. Роботи використовуються у промисловості (роботизовані руки), у транспорті (автономні автомобілі) й у побуті (роботизовані пилососи).
«Кухонний робот» – це робот?
Кухонний робот, незважаючи на назву, технічно не є роботом, оскільки не сприймає навколишнього середовища і не приймає ніяких автономних рішень.
Слово «робот» походить від слова «robota» (праця підданих) і вперше було вжито у п’єсі R.U.R. (Rossum’s Universal Robots) Карела Чапека в 1920 році. Android — це термін для гуманоїдних роботів, тобто роботів, які мають людську форму. Однак робот, як правило, не обов’язково має виглядати людиною, для багатьох застосувань це не є ані необхідним, ані бажаним (як-от, робот-пилосос). Але він повинен мати певну механічну частину. (Для суто віртуальних роботів, тобто програм, що автоматизують діяльність, іноді використовується термін бот.)
Частини робота
Сенсори дозволяють роботу сприймати навколишнє середовище. Кілька прикладів:
- GPS = позиціонування за допомогою супутників, що обертаються навколо Землі
- Радар = вимірювання відстаней до навколишніх об’єктів за допомогою радіохвиль
- Лідар = вимірювання відстаней до навколишніх об’єктів за допомогою світлових променів (вимірює, скільки часу потрібно для їх повернення)
- Сонар = вимірювання відстані за допомогою звукових (зазвичай ультразвукових) хвиль
- Камера = захоплення зображення, корисне для категоризації об’єктів
- Інерціальний вимірювальний блок (англ. Inertial Measurement Unit, IMU) поєднує в собі гіроскоп, акселерометр (та іноді також магнітометр) для визначення орієнтації, швидкості та прискорення машини
Блок керування, зазвичай реалізований через одночіповий комп’ютер (мікроконтролер), дозволяє роботу обробляти інформацію від датчиків і вирішувати, як реагувати.
Ефектори дозволяють роботу впливати на навколишнє середовище (наприклад, роботизовані руки та щупальця) і пересуватися в ньому (як-от, колеса, ремені, роботизовані ноги).
Штучний інтелект
Штучний інтелект використовується в робототехніці, наприклад, для планування маршруту, локалізації роботів і розпізнавання навколишніх об’єктів. Ці завдання ускладнюються тим фактом, що ми не знаємо точного стану світу (через неточні вимірювання датчиків) і того, як світ буде розвиватися (як-от, рух інших автомобілів). Сам робот також є джерелом невизначеності, оскільки виконання дій не зовсім точне (обертання на 89° замість заданих 90°). Ось чому для рішень використовуються імовірнісні моделі, які також можуть моделювати невизначеність. З кожним новим вимірюванням датчиків ця невизначеність зменшується, з плином часу і руху, навпаки, зростає.
При плануванні необхідно враховувати конструктивні обмеження, через які робот може не впоратися з довільним планом (так, автомобіль не може рухатися по довільній кривій, тому ускладнюється паркування). Тому планування іноді виконується не в геометричному просторі світу, а в конфігураційному просторі даного робота, в якому окремі стани описують повний стан робота (наприклад, його положення, обертання, швидкість).
ВгоруКомп'ютерний зір
Комп’ютерний зір – це галузь штучного інтелекту, яка займається отриманням інформації з даних зображень. Дані зображення – це не лише фотографії та зображення, а й відео, зображення медичних вимірювань (рентген, ультразвук) і зображення з різних датчиків (радар, ехолот). Типовими завданнями комп’ютерного зору є:
- розпізнавання зображень – визначення категорії об’єкта (вид квітки на фото, рукописний знак)
- виявлення об’єктів – ідентифікація різних об’єктів, включаючи їх розташування на зображенні (пішоходи, обличчя, дорожні знаки)
- сегментація зображення – поділ зображення на окремі частини або об’єкти (поділ переднього та заднього плану фото, фарбування різних типів тканин)
Приклади застосування комп’ютерного зору
- розпізнавання відсканованого тексту (OCR від англ. optical character recognition)
- розпізнавання осіб (ідентифікація людей на фото)
- визначення виду рослини чи тварини за фото
- аналіз медичних вимірювань (як-от, рентгенівських зображень)
- контроль якості продукції (автоматичне виявлення дефектів)
- виявлення подій на відео (наприклад, крадіжки, зафіксовані системою камер безпеки)
- пошук зображень за текстовим описом (або зображень, схожих на задане зображення)
- автономні автомобілі (як-от, виявлення кордонів доріг, інших автомобілів, пішоходів, розпізнавання дорожніх знаків)
- роботи, які сприймають оточення та реагують на нього (наприклад, можуть схопити предмет)
Комп’ютерний зір неможливо вирішити за допомогою рукописних правил. (Навіть один і той самий об’єкт щоразу виглядає по-різному залежно від того, наскільки він далеко, як знятий, освітлений чи частково закритий.) Ось чому машинне навчання використовується, коли програма вивчає загальні ознаки різних об’єктів на великій кількості прикладів. (Якщо програма має навчитися класифікувати різні види тварин, їй потрібно вивчити фотографії всіх видів, які вона має розрізняти, в ідеалі у багатьох різних ситуаціях.)
Основними ознаками зображень можуть бути, наприклад, краї та кути. Такі функції можна отримати з вихідного зображення за допомогою згортки, яка є трансформацією зображення, у якій кожен піксель замінюється зваженою сумою значень пікселів поблизу нього. Значення ваг можуть бути різними і називаються ядром згортки (англ. kernel). Раніше було звичним визначати ці функції вручну та використовувати їх як вхідні дані для простої моделі.
Сьогодні використовуються більш складні моделі, які автоматично навчаються самостійно виділяти відповідні ознаки. Однак вони вимагають навіть більшої кількості прикладів, ніж простіші моделі, які використовують функції, введені вручну. Найчастіше використовуються глибокі нейронні мережі. Нейронні мережі частково натхненні структурою мозку, але по суті це просто складна математична функція з багатьма параметрами, значення яких вивчаються з даних. Слово «глибокий» тут стосується того факту, що мережі містять багато шарів, які поступово охоплюють більш складні особливості та візерунки (краї → базові геометричні фігури → складні форми → «котоподібність» тощо). Згорткові нейронні мережі, які містять згорткові шари, добре підходять для завдань комп’ютерного зору. Вагові коефіцієнти згортки не надаються заздалегідь, вони вивчаються з даних.
ВгоруМетоди штучного інтелекту
Багато алгоритмічних задач можна сформулювати як один з кількох типів завдань штучного інтелекту, які включають планування (пошук найкоротшого шляху), виконання умови (як-от, судоку), оптимізація (знаходження мінімуму заданої функції), передбачення (оцінка значення або категорії, наприклад, виявлення спаму) та генерація (як-от, відповіді на запитання). Як тільки нам вдається сформулювати проблему як один із цих типів, ми можемо використовувати стандартні процедури та алгоритми для її вирішення:
- Завдання планування можна вирішити за допомогою техніки пошуку у просторі станів (як-от, пошук у глибину чи ширину).
- Завдання на виконання умов можна розв’язувати, наприклад, комбінацією розповсюдження обмеження та зворотного відстеження (backtracking).
- Проблеми оптимізації можна вирішити шляхом поступового створення рішення (систематично чи методом голоду) або шляхом поступового вдосконалення одного чи кількох рішень (локальний пошук, генетичні алгоритми).
- Для прогнозів чи генерацій використовується машинне навчання, тобто програми, які навчаються на основі даних або досвіду. (Ми присвячуємо цій величезній темі окремий розділ.)
Завдання та методи штучного інтелекту
На перший погляд кожна нова задача виглядає по-різному, але при відповідному абстрагуванні часто виявляється, що розв’язується один з відомих типів задач, для яких ми можемо використовувати стандартні процедури та алгоритми.
Типи завдань штучного інтелекту
До типів завдань, які вирішуються у штучному інтелекті, належать:
- планування – пошук (найкоротшої) послідовності дій, які приведуть нас до мети (пошук виходу з лабіринту, збирання кубика Рубіка, планування подорожі автомобілем до заданого місця, розв’язування Сокобану, Тачок тощо)
- виконання умов – пошук значень змінних, які відповідають різним пов’язаним обмеженням (створення шкільного розкладу, розв’язування судоку та подібні логічні завдання)
- оптимізація – пошук значень змінних, що мінімізують або максимізують вказану функцію (упаковка рюкзака з найбільшим значенням вибраних елементів, у пошуках рецепту найкращого печива)
- водіння – пошук стратегії, що прописує відповідні дії для різних ситуацій (гра в шахи, водіння автомобіля між двома перехрестями)
- прогноз – визначення категорії або значення якогось атрибута певного зразка (виявлення спаму, розпізнавання рослини на фото, оцінка завтрашніх опадів)
- генерація – створення тексту або зображення на основі іншого тексту або зображення (відповіді на запитання, машинний переклад, генерація описаного зображення)
Багато проблем є комбінацією завдань кількох типів. Наприклад, задача комівояжера (задача знайти найкоротший маршрут, який проходить через усі вказані міста та повертається до початкової точки) передбачає планування, оптимізацію та обумовленість.
Характеристики середовища
Крім того, ми можемо розрізняти завдання відповідно до властивостей середовища, з яким взаємодіє програма:
- дискретне проти безперервного (Чи існує лише зліченна кількість можливих станів і дій, чи існує безперервний спектр?)
- повне проти такого, що спостерігається частково (Чи маємо всю інформацію про поточний стан?)
- статичне проти динамічного (Чи розвивається середовище, навіть коли ШІ думає?)
- детерміноване проти стохастичного (Чи розвиток чітко визначається вжитими діями чи випадковість відіграє роль?)
- дружнє проти ворожого (Чи середовище грає проти нас?)
Приклади середовищ
Більшість суто логічних настільних ігор для двох гравців (шахи, го, шашки) є дискретними, повністю доступними для спостереження, статичними, детермінованими та змагальними. Багато карткових ігор (Rain, Poker, Bang!) можна спостерігати лише частково, ігри в кості є стохастичними. Водіння автономного автомобіля є безперервним, частково спостережуваним, динамічним і стохастичним, але не змагальним.
Методи штучного інтелекту
Ці завдання розв’язуються поєднанням різних підходів:
- декомпозиція на простіші підзадачі
- систематичне тестування можливостей (груба сила та методи пошуку у просторі станів)
- поступове вдосконалення рішення (наприклад, локальний пошук і генетичні алгоритми)
- логічний та ймовірнісний висновок (імовірність важлива для роботи з невизначеністю)
- використання експертного розуміння та евристики (правила, які не завжди застосовуються, але часто допомагають)
- навчання на основі даних або досвіду (машинне навчання)
Перегляд простору станів
Пошук у просторі станів є основою багатьох методів штучного інтелекту, він використовується, наприклад, для вирішення логічних завдань, вибору оптимального ходу, пошуку найкоротшого шляху або планування дій робота.
Простір станів завдання складається зі станів (можливих конфігурацій завдання) і дій (переходів між станами). Один із станів є початковим і принаймні один стан є цільовим. Переходи можуть мати пов’язану ціну.
Простір станів як граф
Простір станів можна представити значним орієнтованим графом, вершини якого відповідають станам, а ребра — діям. Граф простору станів занадто великий для більшості практичних завдань, щоб побудувати його повністю у пам’яті, але деякі алгоритми пошуку поступово створюють частину цього графа.
План – це будь-яка послідовність дій. Рішення завдання – це такий план, який переводить нас із початкового стану до цільового. Оптимальне рішення – це рішення, яке має найменшу вартість. (Ціна плану найчастіше є сумою цін окремих переходів.)
Приклад простору станів (ельф на сітці)
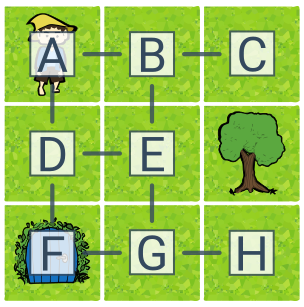
Завдання – завести ельфа у будинок. Простір станів завдання має 8 станів (A–H) і 4 дії (вліво, вправо, вниз, вгору). Початковий стан — А, цільовий — F. Оптимальним рішенням завдання є, наприклад, план вниз—вниз. Прикладом рішення, яке не є оптимальним, є праворуч—вниз—ліворуч.
Спроба всіх варіантів
Найпростішим алгоритмом, який завжди знаходить рішення (якщо воно існує), є згенерувати та перевірити. Цей алгоритм генерує всі можливі плани та перевіряє, чи є вони вирішенням проблеми. Отже, це використання грубої сили — методу розробки алгоритму, заснованого на спробі всіх можливостей. Основним недоліком грубої сили є її трудомісткість. Кількість можливих планів експоненціально зростає з довжиною плану.
Скільки існує різних планів?
Якщо у нас 4 різні дії (P – вправо, D – вниз, L – вліво, H – вгору), то є 4 плани довжини 1, але вже 4^2 плани довжини 2 (PP, PD, PL, PH, DP, DD, DL, DH, LP, LD, LL, LH, HP, HD, HL, HH), плани 4^3 довжиною 3, плани 4^4 довжиною 4 тощо.
Загалом існує k^n планів довжини n з k діями. Наприклад, для 3 можливих дій є 3^5 = 243 планів з 5 кроків, утричі більше планів з 6 кроків, 3^6 = 729, а плани з 20 кроків становлять 3^{20 }, що становить кілька мільярдів.
Дерево пошуку
Однак багато планів можуть бути взагалі нездійсненними, або вони неодноразово повертаються до того самого стану. Тому більш вигідно безперервно тестувати плани після кожної дії – як тільки ми досягаємо тупикової ситуації або раніше дослідженого стану, нам не потрібно досліджувати будь-які інші плани, починаючи з цієї послідовності дій.
Дерево пошуку – це загальна назва такого способу пошуку, коли ми поступово будуємо та оцінюємо плани після кожної дії. Процедуру пошуку плану можна описати за допомогою дерева пошуку, в якому вершини представляють плани (і водночас стан, до якого ми приходимо, виконуючи план), а орієнтовані ребра представляють дії, які розширюють попередній план на один крок. Дерево пошуку фіксує простір станів у міру його поступового виявлення алгоритмом пошуку. Існує кілька варіантів пошуку дерева, які відрізняються планом розширення (тобто який із виявлених станів досліджується наступним).
Пошук у глибину (DFS, англ. Depth First Search) вибирає останній виявлений стан. DFS має добру пам’ять, оскільки запам’ятовує лише плани поточної гілки дерева пошуку.
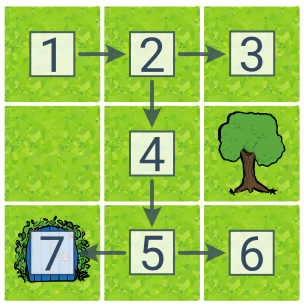
У цьому прикладі ми припускаємо, що DFS намагається виконувати дії за годинниковою стрілкою (праворуч–вниз–ліворуч–вгору). Цифри біля статусів описують порядок появи. Мета була знайдена на кроці 7, а знайдений план складається з 4 кроків (вправо–вниз–вниз–ліворуч).
Пошук у ширину (BFS, англ. Breadth First Search) шукає стани шар за шаром відповідно до кількості дій із початкового стану. Хоча це збільшує складність пам’яті (потрібно запам’ятати більше станів), це краще приводить до найкоротшого рішення.
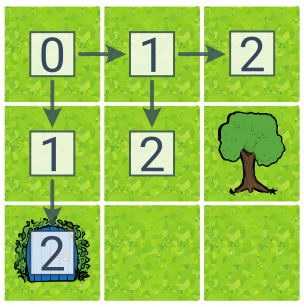
Числа для станів у зразку BFS являють собою відстані від початкового стану, що відповідає порядку обходу «шар за шаром». BFS знайшов оптимальне рішення (вниз–вниз) після дослідження 6 станів.
Uniform Cost Search (UCS, англ. Uniform Cost Search) — це варіант BFS, який дозволяє знайти найдешевше рішення, навіть якщо дії мають різні ціни. Ми вибираємо план із найнижчою ціною для розширення.
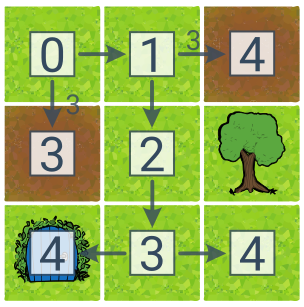
Для демонстрації UCS ми додали два коричневих болота з утричі більшою вартістю переходів на карту. Цифри у квадратах тут відображають вартість плану. У цьому випадку найдешевшим рішенням (з вартістю 4) є праворуч–вниз–вниз–ліворуч, і UCS знаходить його. (BFS поверне рішення вниз–вниз із вартістю 6).
Алгоритм дерева пошуку
Під час використання дерева пошуку ми підтримуємо набір станів, які хочемо дослідити у майбутньому, так званий край. На кожному кроці ми видаляємо один стан із краю та розміщуємо його наступників на краю (тобто стани, які можна досягти з видаленого стану однією дією). Загальна схема пошуку дерева така:
- Поставте початковий стан на край.
- Повторюйте наступні дії, доки не знайдете ціль.
- Видаліть один стан з краю. Якщо це ціль, закінчуйте пошук.
- В іншому випадку розгорніть край, тобто включіть у рішення його наступників.
- Якщо край порожній, шляху до пункту призначення немає.
Згадані варіанти дерева пошуку відрізняються тим, яку стратегію вони використовують для вибору стану з краю (крок 3), тобто як вони реалізують край. Пошук у глибину (DFS) використовує стек (ми беремо останній вставлений стан), пошук у ширину (BFS) — чергу (ми беремо найраніший вставлений стан), а пошук на основі вартості (UCS) — пріоритетну чергу (ми беремо стан із найнижчою ціною найдешевшого плану, що веде до цього стану).
Крім того, щоб уникнути повторного дослідження тих самих станів, ми можемо зберегти набір уже досліджених станів і не розширювати їх знову. Це розширення іноді називають загальним пошуком на графі, щоб відрізнити його від пошуку по дереву без перевірки раніше досліджених станів. Недоліком є збільшення вимог до пам’яті.
Інформований пошук
Пошук можна пришвидшити за допомогою евристики, яка забезпечує оцінку відстані до цілі. Така інформація стосується конкретного завдання. Ми називаємо пошук за допомогою евристики інформованим пошуком. (На відміну від цього ми називаємо алгоритми у попередніх розділах «неінформованими»).
Голодний пошук дотримується лише значення евристики та завжди вибирає дію, яка наближає нас до мети. Якщо є ризик тупикових ситуацій, необхідно поєднати голодний підхід з деревом пошуку (так зване голодне дерево пошуку) – наступним станом вибираємо той, у якого за евристикою найнижча цінова оцінка. Голодний пошук дуже швидкий, але не гарантує знаходження оптимального рішення.
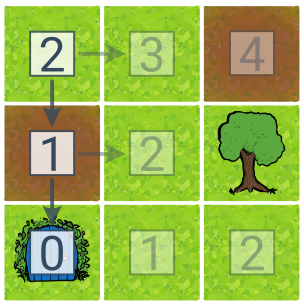
У цьому прикладі голодного дерева пошуку числа для станів відповідають евристичній оцінці вартості до місця призначення. Евристика — це відстань від цілі, яка розраховується як сума відхилень стовпців і рядків. Алгоритм знайшов шлях до місця призначення за два кроки, але це не найдешевший маршрут.
A* пошук („A star“) поєднує пошук на основі вартості (UCS) з евристикою. Це пошук по дереву, де в ролі наступного стану ми обираємо стан, який має найменшу суму ціни на даний момент і евристичну оцінку ціни, що залишилася до цілі. Якщо евристика оптимістична (забезпечує нижчу оцінку справжньої ціни), тоді A* досягне оптимального рішення і знайде його тим швидше, чим ближче евристика надає оцінки справжньої ціни.
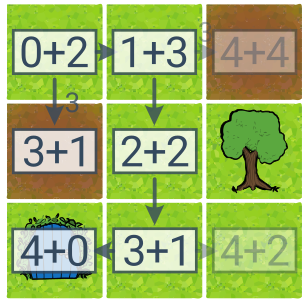
Сума станів описує пріоритет для A*: [поточна ціна] + [орієнтовна ціна, що залишилася]. A* знайшов оптимальне рішення, досліджуючи менше штатів, ніж UCS (6 замість 8).
ВгоруВиконання умов
Багато завдань ШІ можна сформулювати як виконання умов. Завдання виконання умов задається набором змінних, їх доменами (можливими значеннями) і набором умов для комбінацій значень змінних. Оцінка (присвоєння значень деяким змінним) є рішенням проблеми, якщо воно повне (присвоює значення всім змінним) і узгоджене (не порушує жодної умови). Іноді також вказується цільова функція, яка визначає значення рішення, яке ми хочемо оптимізувати.
Галузь інформатики, яка займається цими завданнями, називається програмуванням з обмеженнями. Виконання умов є суттю багатьох логічних задач (як-от, задача про 8 ферзів, задача Ейнштейна, алгеброграма). На Знаємо це ви можете спробувати судоку, паркани і бінарні кросворди. Практичне застосування цих знань – це компіляція конфігурацій продукту, які відповідають заданим обмеженням, або створення розкладів (шкільних розкладів, маршрутів транспорту, виробничої логістики, сітки турнірних матчів).
Задача про 8 ферзів
Завдання розставити 8 ферзів на шахівниці так, щоб жоден з них не загрожував жодному іншому. (Ферзя можна пересувати на будь-яку кількість квадратів по горизонталі, вертикалі та діагоналі.) Задачу можна узагальнити до «проблеми N ферзів», які ми маємо розмістити на N×N шахівниці.
Задача Ейнштейна
Завдання визначення властивостей кількох об’єктів на основі обмеженої інформації. Найвідоміша версія завдання описує п’ять різних за кольором будинків, що стоять поруч, з різними власниками за національністю, у яких різні улюблені напої, марка сигарет і домашня тварина. При цьому в нас є 15 рядків інформації типу «Англієць живе в червоному будинку» чи «Норвежець живе біля синього будинку».
Алгеброграма
Завдання полягає в тому, щоб замінити літери різними цифрами, щоб виконувалася задана формула. Приклад: SEND + MORE = MONEY.
Розв’язування задач на виконання умов
Після того, як ми змоделювали проблему як задачу на виконання умови, можна використовувати загальні процедури для її вирішення. Наївна перевірка всіх можливих оцінок (згенерувати та перевірити) зазвичай буде надто повільною, оскільки кількість можливих оцінок експоненціально зростає разом із кількістю змінних. Тому зазвичай використовується поступове створення рішення з поширенням обмежень або поступове вдосконалення повної оцінки.
Які проблеми важкі?
Складність задач з обмежувальними умовами залежить від співвідношення кількості обмежень до кількості змінних. Якщо цей коефіцієнт дуже високий або, навпаки, дуже низький, то знайти рішення (або виявити, що його немає) буде легко. Уявіть собі судоку, де заповнені майже всі поля (числа, що залишилися, визначити легко), або навпаки, заповнено лише кілька полів (різних рішень багато).
Покрокова побудова рішення
Цей підхід полягає в систематичному тестуванні можливих оцінок. Однак, на відміну від «генеруй і тестуй», ми оцінюємо окремі змінні поступово і постійно перевіряємо, чи не було порушено якісь умови. Якщо так, ми спробуємо інше значення. Якщо ми вже перепробували всі можливі значення даної змінної, ми повертаємося до попередньої змінної та намагаємося змінити її значення (цих повернень може бути скільки завгодно). Цей алгоритм називається backtracking.
Відповідність умова vs. планування
Завдання виконання умов можна сформулювати як завдання планування, де стани представляють різні оцінки змінних: початковий стан – порожня оцінка, дії відповідають присвоєнню значення одній змінній, а цільовим станом є повна узгоджена оцінка. (Отже, усі рішення знаходяться на однаковій глибині, враховуючи кількість змінних.)
Відмінність від загального завдання планування полягає в тому, що стани і мета мають внутрішню структуру – стан складається зі значень декількох змінних, мета складається з декількох умов. Завдяки цій внутрішній структурі завдання виконання умов можна вирішувати значно ефективніше, ніж за допомогою загальних методів пошук у просторі станів. Так, ми можемо визнати, що знаходимося в тупиковій гілці, коли якась умова не виконується. Друга відмінність полягає в тому, що нас цікавить не план (послідовність дій, що ведуть до мети, наприклад, порядок заповнення сіток судоку), а стан мети (оцінка змінних, як-от, виконане судоку).
Зворотне відстеження (backtracking) — це по суті глибоке сканування (DFS) із ранньою перевіркою на порушення умов. (Друга відмінність полягає в тому, що порядок дій не має значення — отримане рішення однакове, незалежно від того, чи спочатку ми присвоюємо значення змінній A чи B. Тому, коли виконується пошук із поверненням, нам потрібно шукати лише один порядок змінних. )
Евристика для вибору змінної та її значення має значний вплив на швидкість зворотного пошуку. Для вибору змінної використовується принцип ранньої відмови: ми вибираємо змінну, для якої важко знайти значення (наприклад, ту, що має найменший домен). Навпаки, принцип раннього успіху більше підходить для вибору значень, тобто вибору, який, скоріше за все, може бути частиною рішення (як-от, таке значення, яке спричиняє найменшу фільтрацію доменів). Причина протилежних принципів вибору змінних і значень полягає в тому, що ми закінчуємо циклом усіх змінних, але не значень.
Рекурсивний пошук можна значно пришвидшити шляхом поширення обмежень. Після кожного вибору значення ми виконуємо фільтрацію домена, зменшуючи кількість майбутніх значень змінних, які потрібно буде спробувати.
Поширення обмежень
З доменів змінних ми можемо безпечно видалити значення, для яких умова не може бути виконана (немає значень інших змінних в умові, для яких застосовувалася б умова). (Судоку: коли цифра вже десь розміщена, ми можемо викреслити її з доменів усіх полів у тому самому рядку, стовпці та квадраті.) Якщо в домені змінної залишилося лише одне можливе значення, то ми знаємо частину рішення.
Ми можемо неодноразово перевіряти умови, поки не вдасться викреслити деякі значення. У рідких випадках (легке судоку) повне рішення можна отримати шляхом повторної фільтрації, але частіше ми лише спрощуємо завдання, а потім нам потрібно спробувати різні можливі значення (ось чому поширення обмежень зазвичай використовується у поєднанні з пошуком з поверненням).
Ми можемо досягти більш вираженої фільтрації, якщо перевіряємо одночасно виконання кількох умов, а не завжди однієї (але це збільшує обчислювальну складність).
Поступове поліпшення
Альтернативою поступовій побудові рішення є варіант розпочати з повної оцінки (лише випадкової) і поступово покращувати її з невеликими коригуваннями. Таким чином, оцінка є повною, але не послідовною. Поліпшення – це зміна оцінки, яка зменшує кількість порушених умов. Алгоритми поступового вдосконалення можна розділити на дві категорії залежно від того, чи працюють вони з однією оцінкою за раз (локальний пошук) чи з кількома одночасно (пошук сукупності).
Локальний пошук працює з однією оцінкою, яку поступово покращує. Сукупність усіх оцінок, які відрізняються від нинішніх однією зміною, ми називаємо оточенням. Метод найбільшого підйому (алгоритм сходження) вибирає з оточення рейтинг, який приводить до найбільш значного покращення. За допомогою цієї процедури ми швидко досягаємо локального оптимуму, коли всі навколишні умови є гіршими. Однак локальний оптимум може не бути глобальним оптимумом, зокрема він може не бути допустимим рішенням.
Тому необхідно використовувати метаевристики, які вносять елемент випадковості у пошук і, таким чином, дають шанс вийти з локального оптимуму. Прикладом метаевристики є імітований відпал, у якому ми вибираємо випадковим чином із середовища; якщо нова оцінка є покращенням, ми приймаємо її, якщо це не покращення, ми приймаємо її з певною ймовірністю, яка поступово зменшується. Проста метаевристика також полягає у багаторазовому запуску локального пошуку з різних випадкових початкових значень.
У пошуку сукупностей ми покращуємо багато оцінок одночасно. Це дає змогу вибрати найкращу із поточної сукупності та, можливо, поєднати різні оцінки. Прикладом є генетичні алгоритми, створені за принципом еволюції. Оцінки, які продовжуються до наступного покоління, вибираються відповідно до їх якості, об’єднуються («схрещування») і, можливо, дещо змінюються випадковим чином («мутація»). Інші природничі алгоритми, які використовують значну кількість взаємодіючих агентів, що представляють повні оцінки, також належать до цієї категорії. (Наприклад, у «оптимізації мурашиної колонії» кожна мураха має пов’язану оцінку і випромінює феромонний слід різної сили залежно від її якості. Що краща ця оцінка, то ймовірніше, що інші мурахи спробують отримати подібну.)
ВгоруОптимізація
Оптимізація означає пошук найкращого рішення. Ми шукаємо значення оптимізованих змінних, при яких зазначена цільова функція є найвищою (максимум) або найменшою (мінімум). Оптимізація використовується, наприклад, у плануванні виробництва, транспортному розкладі, проєктуванні телекомунікаційних мереж і навчанні моделей у машинному навчанні.
Оптимізаційні задачі
Проблеми максимізації та мінімізації можна розв’язувати за допомогою тих самих методів, оскільки кожна задача максимізації може бути перетворена в задачу мінімізації (і навпаки) інвертуванням цільової функції. Однак різні методи відрізняються тим, чи можна їх використовувати в дискретному чи безперервному просторі (у безперервному просторі змінні можуть набувати довільних дійсних чисел) і чи може проблема містити обмежувальні умови.
Приклади оптимізаційних задач
Проблема з рюкзаком. Виберіть комбінацію предметів, яка поміститься в рюкзак обмеженої місткості, щоб максимізувати загальну вартість.
Проблема продавця. Знайдіть найкоротший маршрут, який проходить через усі вказані міста та повертає до початкової точки.
Планування. Знайдіть оптимальний (найкоротший, найдешевший) розклад діяльності в часі з урахуванням заданих ресурсів і обмежень.
Машинне навчання. Виберіть параметри моделі (наприклад, вагові коефіцієнти нейронної мережі), мінімізуючи помилку прогнозування даних навчання.
Проблема шоколадного печива. Знайдіть найкращий рецепт шоколадного печива.
Систематичний пошук
Найпростіший підхід — спробувати всі варіанти (груба сила). У безперервному просторі можливості нескінченні, але можна систематично пробувати всі комбінації значень із певною роздільною здатністю (пошук у сітці). Цей підхід застосовний лише до дуже невеликих проблем, оскільки кількість можливостей експоненціально зростає з кількістю змінних. Під час розв’язання задачі про рюкзак ми можемо брати або не брати кожен об’єкт, тому існує 2^n можливих комбінацій об’єктів.
Ефективніше призначати значення змінним поступово і постійно оцінювати найкраще можливе значення рішення з заданим частковим призначенням. Коли ця межа гірша за найкраще рішення, знайдене на даний момент, ми можемо пропустити всю гілку та бути впевненими, що ми не пропустили оптимальне рішення. Цей варіант пошуку дерева називається методом **розгалуження та зв’язку*. Щоб вибрати наступний стан для дослідження, можна використати голодний критерій – стан із найкращим граничним значенням (або іншою стратегією перегляду простору станів).
Голодний і випадковий пошук
Систематичний пошук гарантує знаходження глобального оптимуму, але дуже часто надто повільний для практичних завдань. Для прискорення необхідно відмовитися від вимоги оптимального рішення, на щастя, для більшості практичних завдань достатньо рішення, яке є «досить хорошим». Потім для прискорення можна використовувати голод і випадковість.
Голодний пошук вибирає значення для кожної змінної, яке здається найкращим на даний момент, і не повертається до цих рішень. Під час вирішення проблеми з рюкзаком ми могли брати предмети з найвищим співвідношенням ціна/вага один за одним, поки вони не помістяться в рюкзак. Голодний пошук дуже швидкий, але знайдене рішення може бути дуже поганим. Між крайнощами голодного пошуку (випробування одного шляху) і систематичного пошуку дерева (випробування всіх шляхів) існує променевий пошук (випробування фіксованої кількості шляхів). Променевий пошук залишає лише фіксовану кількість найкращих станів на кожному рівні дерева та відкидає інші.
Випадковий пошук перевіряє випадково вибрані рішення (замість усіх можливих). Існують більш складні техніки, які поступово збільшують ймовірність вибору рішень у перспективних областях – вони намагаються збалансувати дослідження недосліджених областей (випадковість) і використання інформації про більш досліджені (голод). Цей компроміс між дослідженням і використанням є загальним принципом, який можна зустріти у багатьох алгоритмах оптимізації.
І голодний пошук, і випадковий також використовуються у методах поступового вдосконалення, які ми розберемо у наступних розділах.
Локальний пошук
Альтернативою поступовому створенню рішення є початок з довільного рішення та поступове покращення його невеликими змінами. Цей підхід називається локальним пошуком. Ми називаємо набір найближчих рішень, які відрізняються від поточного однією зміною, оточенням. (Під час розв’язання задачі про рюкзак до оточення можуть входити, наприклад, ті комбінації, які відрізняються щонайбільше одним доданим і одним вилученим предметом.) Існують різні евристики для вибору наступного рішення з оточення. Алгоритм підйому вибирає деякі поліпшувальні рішення або найкраще рішення з оточення (цей варіант алгоритму підйому називається методом максимального підйому).
Використовуючи ці голодні евристики, ми швидко приходимо до локального оптимуму, тобто рішення, яке є найкращим у своєму оточенні, але не обов’язково має бути глобальним оптимумом. Шанси знайти глобальний оптимум можна збільшити за допомогою випадковості. Імітація відпалу випадково вибирає з оточення: якщо нове рішення є поліпшенням, то ми його приймаємо, якщо це не поліпшення, то приймаємо його з певною імовірністю, яка поступово зменшується.
Еквівалентом локального пошуку в безперервному просторі є градієнтний спуск. У безперервному просторі часто можна обчислити напрямок, у якому цільова функція спадає або зростає найшвидше (так званий градієнт), тоді немає потреби тестувати різні рішення поблизу. Градієнтний спуск зазвичай використовується у машинному навчанні, наприклад, для оптимізації ваг нейронної мережі.
Пошук сукупностей
Під час пошуку сукупностей ми вдосконалюємо багато рішень одночасно. Це дає змогу вибрати найкраще рішення з поточної сукупності та, можливо, комбінувати різні рішення. Прикладом є генетичні алгоритми, створені за принципом еволюції. Розв’язки, що продовжують наступне покоління, вибираються відповідно до їх якості (значення цільової функції), комбінуються («схрещування») і, при необхідності, злегка випадково змінюються («мутація»).
Ця категорія також включає алгоритми ройового інтелекту, натхненні груповою поведінкою виду (зазвичай під час пошуку їжі). Ці алгоритми використовують велику кількість простих агентів, що представляють різні рішення, які опосередковано взаємодіють один з одним через спільну пам’ять. Наприклад, в оптимізації колонії мурашок кожна мураха має пов’язане рішення та випромінює феромонний слід уздовж свого маршруту, який тим сильніший, чим краще рішення. Усі сліди феромонів разом утворюють спільну пам’ять, за якою потім йдуть інші мурахи (вони віддають перевагу шляхами з більш вираженим слідом феромонів, які зарекомендували себе в минулому).
ВгоруМашинне навчання
Машинне навчання — це підполе штучного інтелекту, яке займається створенням програм, що навчаються на даних. Машинне навчання пов’язане з темою роботи з даними, особливо з їх збором і записом.
У рамах Знаємо інформатику ми розділяємо цю тему таким чином:
- основи машинного навчання (основний принцип машинного навчання, відмінність від класичного програмування, використання машинного навчання)
- типи завдань, які можна вирішити за допомогою машинного навчання (як-от, класифікація, регресія, кластеризація)
- методи вирішення цих завдань (навчання з учителем і без нього, посилене навчання, нейронні мережі та інші моделі, алгоритми навчання)
- оцінка вивчених моделей (розрізнення між узагальненням і простим запам’ятовуванням, розпізнавання навчання та перенавчання, вибір та інтерпретація відповідних показників для порівняння моделей)
- викривлення (упередження) у машинному навчанні (що це таке, як це розпізнати та що з цим можна зробити)
Упередженість машинного навчання
Спотворення (іноді також упередженість, англ. bias) означає систематичну помилку, яка призводить до несправедливих наслідків для різних груп. Це не обов’язково мають бути групи людей, термін спотворення також використовується для ситуації, коли, наприклад, модель значно частіше передбачає одну категорію (як-от, груші), навіть якщо інші категорії (як-от, яблука) трапляються так само часто.
Спотворення моделі можуть сприяти упередженості (модель, що передбачає академічну успішність у певній галузі з використанням гендерної інформації) та призвести до дискримінації (якщо цю модель використовуватимуть для прийняття рішень про вступ до університету).
Спотворення моделі здебільшого викликано спотвореними даними, оскільки модель дізнається лише те, що вона бачить у даних. Вибіркове спотворення виникає, коли дані не представляють належним чином усі типи випадків. Якщо ми тренуємо розпізнавання взуття лише на чоловічому взутті, модель не розпізнає жіноче взуття. Спотворення відповідей може статися, наприклад, через упередження анотаторів або небажання респондентів розповідати правду. В опитуваннях люди часто коригують свої відповіді про себе відповідно до соціальних очікувань.
Спотворення може бути важко виявити, оскільки, на відміну від перенавчання, воно зазвичай не проявляється в нижчому рівні успіху на тестових даних. У звичайній процедурі дані для тестування та навчання надходять з одного джерела, тому вони містять однакове упередження.
Щоб зменшити ризик упередженості, бажано постійно перевіряти якість даних. Так, ми маємо переконатися, що зібрані дані включають усі типи випадків і що кожна категорія представлена подібною кількістю прикладів, подібної якості та в подібних контекстах. Під час анотування даних бажано, щоб це робили люди з різних груп (як-от, чоловіки та жінки). Також корисно оцінити поведінку моделі для різних підгруп даних (наприклад, для чоловіків і жінок, різних вікових груп, меншин) і постійно стежити за поведінкою моделі навіть після розгортання.
ВгоруМашинне навчання: поняття
Ось огляд термінів, які нерідко зустрічаються у сфері машинного навчання. Багато з них ще не мають усталених українських відповідників, тому в текстах часто наведено й англійські терміни(вказано нижче курсивом у дужках). Ви можете знайти більш детальне пояснення окремих термінів у підтемах з машинного навчання.
| поняття | опис |
|---|---|
| машинне навчання | навчальні програми на основі даних |
| модель | відображення входів і виходів (вирішення проблеми машинного навчання) |
| набір даних (dataset) | дані для навчання моделі |
| приклад (example) | один повний вхід моделі (рядок набору даних) |
| атрибут (feature) | інформація про приклади, які використовує модель (стовпець набору даних) |
| марка (label) | правильний висновок для наведеного прикладу |
| анотація даних | присвоєння правильних висновків (марок) |
| марковані дані | дані з бажаним результатом (маркою) |
| предикція | прогноз, оцінка (вихід моделі) |
| висновок | складання оцінок за допомогою навченої моделі |
| контрольоване навчання (supervised learning) | підхід машинного навчання з використанням маркованих даних |
| неконтрольоване навчання (unsupervised learning) | підхід машинного навчання з використанням немаркованих даних |
| напівконтрольоване навчання (semi-supervised learning) | підхід машинного навчання з використанням як маркованих, так і немаркованих даних |
| поглиблене навчання, навчання зі зворотнім зв’язком (reinforcement learning) | навчання через взаємодію з навколишнім середовищем, включаючи зворотній зв’язок щодо вжитих дій |
| класифікація | завдання визначити, чи належить приклад до однієї з кількох попередньо визначених категорій (як-от, жанр книги) |
| регресія | завдання на визначення числового значення для заданого прикладу (як-от, оцінка книги) |
| сортування (ranking) | завдання організації прикладів (як-от, рекомендації книг) |
| виявлення аномалії | завдання виявлення прикладів, які значно відрізняються від решти даних |
| кластеризація (clustering) | завдання поділу прикладів на групи (кластери) зі схожими властивостями |
| генеративний штучний інтелект (generative AI) | моделі, що генерують складні результати, такі як відповіді чи зображення |
| лінійна модель | модель, що визначає результат на основі зваженої суми атрибутів |
| дерево рішень (decision tree) | модель, що визначає результат на основі послідовності умов |
| випадковий ліс (random forest) | модель, що складається з багатьох дерев рішень |
| нейронна сіть | модель, дещо натхненна структурою мозку, що складається з багатьох взаємопов’язаних «нейронів», які виконують просту функцію, зазвичай організовану в шари |
| глибоке навчання (deep learning) | вивчення нейронних мереж з багатьма шарами |
| велика мовна модель (Large Language Model, LLM) | великомасштабна нейронна мережа, що передбачає ймовірність наступного слова (як-от, GPT) |
| трансформатор (transformer) | тип нейронної мережі, що забезпечує ефективне навчання на великих даних (T у GPT означає трансформатор) |
| параметри, ваги | значення моделей, які можна змінювати у процесі навчання |
| градієнтний спуск (gradient descent) | алгоритм навчання, який багаторазово змінює параметри моделі в напрямі найбільшої зміни (градієнта) функції помилки |
| стохастичний градієнтний спуск (SGD) | ефективний варіант градієнтного спуску використовує елемент випадковості |
| навчальні дані | дані, які використовуються для навчання моделі |
| тестувальні дані | дані, які використовуються для оцінки моделі |
| генералізація | здатність передбачати правильні результати навіть для нових даних (тобто узагальнювати) |
| меморизація | лише запам’ятовування правильних вихідних даних навчання |
| недонавчання (underfitting) | модель має високий рівень помилок, оскільки вона занадто проста для поставленого завдання |
| перенавчання (overfitting) | точне запам’ятовування навчальних даних за рахунок здатності до узагальнення |
| регулярізація | методи запобігання перенавчанню, наприклад, штрафування за складність моделі |
| упередженість, (bias) | систематична помилка, що призводить до несправедливих наслідків |
| вибрана упередженість (selection bias) | тип упередженості, коли дані не представляють належним чином усі типи випадків |
| основна модель (baseline) | просте рішення задачі використовується для порівняння з більш складними методами |
| метрика | значення, що виражає якість моделі |
| середньоквадратична похибка (mean squared error) | метрика для задач регресії, середній квадрат відхилення між прогнозованим і фактичним значенням |
| правильність (accuracy) | метрика класифікаційних завдань, частка правильних відповідей |
| точність (precision) | метрика для класифікаційних завдань, скільки з усіх позначених прикладів є позитивними |
| покриття (recall) | метрика для класифікаційних завдань, скільки всіх позитивних прикладів виявила модель |
| матриця невідповідностей (confusion matrix) | таблиця, яка показує, скільки яких категорій було класифіковано і яким чином |
| тензорний блок обробки, TPU (Tensor Processing Unit) | процесори, що спеціалізуються на машинному навчанні |
Методи машинного навчання
Загальний підхід машинного навчання включає вибір обчислювальної моделі для розв’язування заданого завдання, параметри якої ми потім коректуємо під час фази навчання моделі. У темах цього розділу більш детально описано кілька моделей, які часто використовуються у машинному навчанні:
- лінійні моделі – визначають результат за допомогою лінійної функції
- дерева рішень – визначають результат за допомогою серії умов
- нейронні мережі – поєднують велику кількість простих функцій (так звані нейрони)
- імовірнісні моделі – робота з невизначеністю (наприклад, з наївним баєсовим класифікатором)
Лінійна регресія
Регресія (у контексті машинного навчання) — це завдання оцінки числового значення якоїсь величини залежно від одного або кількох атрибутів (наприклад, оцінка ціни квартири на основі її площі). Лінійна регресія – це розв’язання задачі регресії за допомогою лінійної моделі, тобто моделі, яка є лінійною функцією (тобто зваженою сумою) оптимізованих параметрів.
Найпростішим прикладом лінійної регресії є пошук лінії \hat{y} = ax + b, яка найкраще описує зв’язок між x і y координатами вказаних точок D = \{(x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\}. У наведеному вище випадку x – площа, y – фактична ціна квартири, а \hat{y} – оцінка ціни відповідно до моделі. Модель має два параметри (a, b), які необхідно визначити (навчання моделі, оптимізація).
Квадратична похибка
Для того щоб вибрати «найкращу» лінію, нам потрібно встановити функцію помилок, яка описує, наскільки дана лінія відповідає заданим точкам. Найчастіше використовується квадратична похибка, яка визначається як сума квадратів відхилень індивідуальних оцінок від реальності. Цей підхід називають методом найменших квадратів, оскільки ми мінімізуємо суму квадратів. Помилка залежить від параметрів a, b і набору точок D:
E(a, b, D) = \sum_{(x,y) \in D} (\hat{y} - y)^2 = \sum_{(x,y) \in D} (ax + b - y)^2
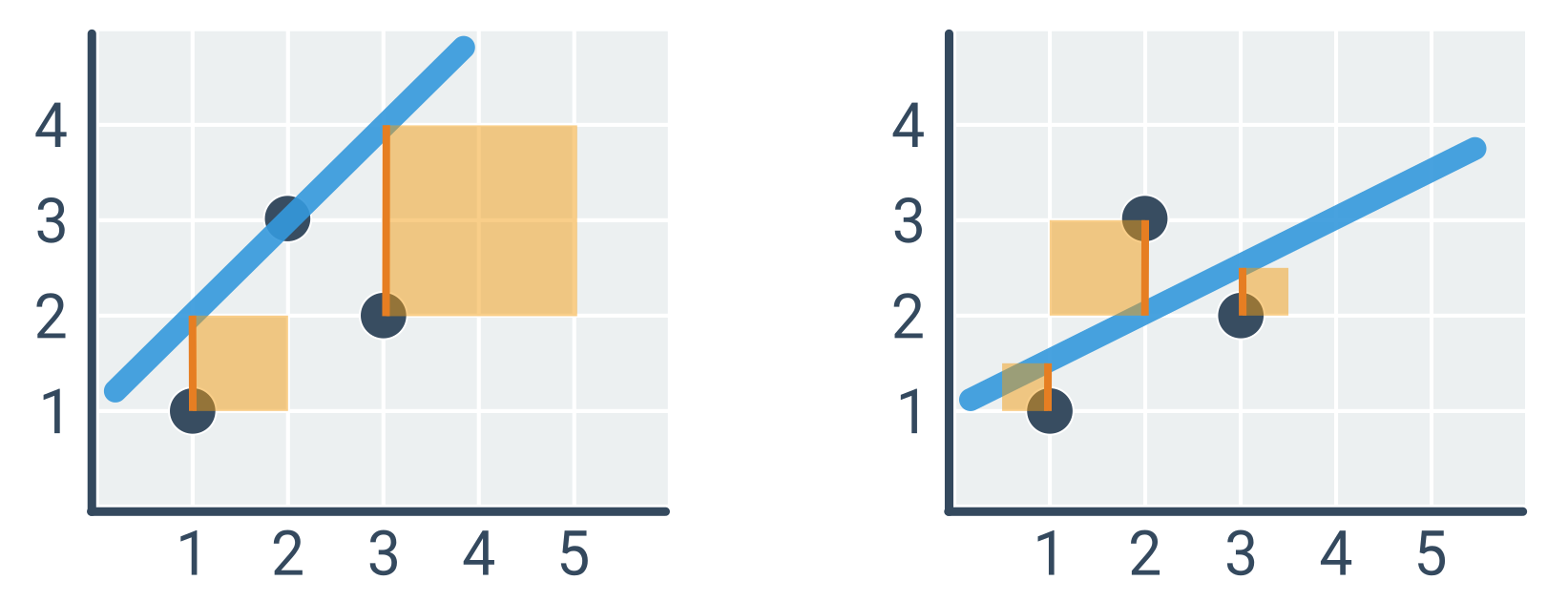
Рядок ліворуч (\hat{y} = x + 1) має квадратичну похибку 1^2 + 2^2 = 5, а рядок праворуч (\hat{y} = 0{ ,}5x + 1) лише 0{,}5^2 + 1^2 + 0{,}5^2 = 1{,}5.
Квадратична помилка чутлива до викидів, тобто точок, які лежать далеко від інших, через потужність відхилень. Іноді викиди просто видаляються. У будь-якому випадку про них краще знати.
Оптимізація параметрів
Завдання полягає в тому, щоб знайти такі значення параметрів a, b, які мінімізують квадратичну похибку. Існує ряд загальних підходів до оптимізації, таких як систематичне тестування різних комбінацій значень параметрів (груба сила) або поступове вдосконалення однієї комбінації параметрів з незначними коригуваннями (градієнтний спуск). Однак у випадку лінійної регресії оптимальні параметри можна визначити аналітично, тобто прямим розрахунком за такими формулами:
a = \frac{\sum (x - \bar{x})(y - \bar{y})}{\sum (x - \bar{x})^2}
b = \bar{y} - a\bar{x}
Суми \sum означають суму по всіх точках (x, y) \in D. \bar{x}, \bar{y} — середні значення x і y. Таким чином, чим вище напрямок a, тим сильніший зв’язок між x і y і чим більші відхилення y відносно відхилень x. Ми отримуємо рівняння для b з інтуїтивно зрозумілого співвідношення між середніми значеннями: \bar{y} = a\bar{x} + b. (Формулу можна отримати через похідну функції квадратичної похибки, яка має бути принаймні рівною 0.)
Приклад розрахунку оптимальної прямої
Ми шукаємо параметри a, b для точок на зображенні вище, тобто D = \{(1, 1), (2, 3), (3, 2)\}.
- \bar{x} = 2, \bar{y} = 2
- (x - \bar{x}) = [-1, 0, 1]
- (y - \bar{y}) = [-1, 1, 0]
- \sum (x - \bar{x})(y - \bar{y}) = (-1) \cdot (-1) + 0 \cdot 1 + 1 \cdot 0 = 1
- \sum (x - \bar{x})^2 = (-1)^2 + 0^2 + 1^2 = 2
- a = 1 / 2 = 0{,}5
- b = \bar{y} - a\bar{x} = 2 - 0{,}5 \cdot 2 = 1
Отже, оптимальна лінія \hat{y} = 0{,}5x + 1 (що відповідає рисунку праворуч).
Загальна лінійна регресія
Зазвичай існує більше атрибутів, на основі яких ми робимо оцінки. Тоді лінійна модель має параметр для кожного атрибута. Наприклад, ми хочемо оцінити швидкість тварини на основі її ваги та довжини кінцівок:
\hat{y} = w_0 + w_1 x_1 + w_2 x_2
\hat{y} — оцінка швидкості, x_1 — вага, x_2 — довжина кінцівки, а w_i — параметри моделі, яку ми вивчаємо (як a, b у випадку моделі з одним атрибутом). Існує формула для розрахунку оптимальних параметрів, яка є узагальненням наведених вище формул для прямої.
Лінійна модель також може мати елементи для нелінійних перетворень атрибутів. Наприклад, щоб оцінити швидкість тварини, ми можемо використати квадрат її ваги: \hat{y} = w_0 + w_1 x_1 + w_2 x_2 + w_3 x_1^2. Важливо, що функція є лінійною щодо параметрів w_i, оскільки інші значення є конкретними числами, отриманими з атрибутів прикладу.
Лінійні моделі добре інтерпретуються. Чим вище абсолютне значення параметра, тим більший вплив пов’язаного атрибута на оцінене значення. Якщо параметр додатний, то оцінене значення зростає зі збільшенням значення атрибута, а якщо параметр від’ємний, то оцінене значення зменшується зі збільшенням значення атрибута.
Вгору