Методи штучного інтелекту
Багато алгоритмічних задач можна сформулювати як один з кількох типів завдань штучного інтелекту, які включають планування (пошук найкоротшого шляху), виконання умови (як-от, судоку), оптимізація (знаходження мінімуму заданої функції), передбачення (оцінка значення або категорії, наприклад, виявлення спаму) та генерація (як-от, відповіді на запитання). Як тільки нам вдається сформулювати проблему як один із цих типів, ми можемо використовувати стандартні процедури та алгоритми для її вирішення:
- Завдання планування можна вирішити за допомогою техніки пошуку у просторі станів (як-от, пошук у глибину чи ширину).
- Завдання на виконання умов можна розв’язувати, наприклад, комбінацією розповсюдження обмеження та зворотного відстеження (backtracking).
- Проблеми оптимізації можна вирішити шляхом поступового створення рішення (систематично чи методом голоду) або шляхом поступового вдосконалення одного чи кількох рішень (локальний пошук, генетичні алгоритми).
- Для прогнозів чи генерацій використовується машинне навчання, тобто програми, які навчаються на основі даних або досвіду. (Ми присвячуємо цій величезній темі окремий розділ.)
Завдання та методи штучного інтелекту
На перший погляд кожна нова задача виглядає по-різному, але при відповідному абстрагуванні часто виявляється, що розв’язується один з відомих типів задач, для яких ми можемо використовувати стандартні процедури та алгоритми.
Типи завдань штучного інтелекту
До типів завдань, які вирішуються у штучному інтелекті, належать:
- планування – пошук (найкоротшої) послідовності дій, які приведуть нас до мети (пошук виходу з лабіринту, збирання кубика Рубіка, планування подорожі автомобілем до заданого місця, розв’язування Сокобану, Тачок тощо)
- виконання умов – пошук значень змінних, які відповідають різним пов’язаним обмеженням (створення шкільного розкладу, розв’язування судоку та подібні логічні завдання)
- оптимізація – пошук значень змінних, що мінімізують або максимізують вказану функцію (упаковка рюкзака з найбільшим значенням вибраних елементів, у пошуках рецепту найкращого печива)
- водіння – пошук стратегії, що прописує відповідні дії для різних ситуацій (гра в шахи, водіння автомобіля між двома перехрестями)
- прогноз – визначення категорії або значення якогось атрибута певного зразка (виявлення спаму, розпізнавання рослини на фото, оцінка завтрашніх опадів)
- генерація – створення тексту або зображення на основі іншого тексту або зображення (відповіді на запитання, машинний переклад, генерація описаного зображення)
Багато проблем є комбінацією завдань кількох типів. Наприклад, задача комівояжера (задача знайти найкоротший маршрут, який проходить через усі вказані міста та повертається до початкової точки) передбачає планування, оптимізацію та обумовленість.
Характеристики середовища
Крім того, ми можемо розрізняти завдання відповідно до властивостей середовища, з яким взаємодіє програма:
- дискретне проти безперервного (Чи існує лише зліченна кількість можливих станів і дій, чи існує безперервний спектр?)
- повне проти такого, що спостерігається частково (Чи маємо всю інформацію про поточний стан?)
- статичне проти динамічного (Чи розвивається середовище, навіть коли ШІ думає?)
- детерміноване проти стохастичного (Чи розвиток чітко визначається вжитими діями чи випадковість відіграє роль?)
- дружнє проти ворожого (Чи середовище грає проти нас?)
Приклади середовищ
Більшість суто логічних настільних ігор для двох гравців (шахи, го, шашки) є дискретними, повністю доступними для спостереження, статичними, детермінованими та змагальними. Багато карткових ігор (Rain, Poker, Bang!) можна спостерігати лише частково, ігри в кості є стохастичними. Водіння автономного автомобіля є безперервним, частково спостережуваним, динамічним і стохастичним, але не змагальним.
Методи штучного інтелекту
Ці завдання розв’язуються поєднанням різних підходів:
- декомпозиція на простіші підзадачі
- систематичне тестування можливостей (груба сила та методи пошуку у просторі станів)
- поступове вдосконалення рішення (наприклад, локальний пошук і генетичні алгоритми)
- логічний та ймовірнісний висновок (імовірність важлива для роботи з невизначеністю)
- використання експертного розуміння та евристики (правила, які не завжди застосовуються, але часто допомагають)
- навчання на основі даних або досвіду (машинне навчання)
Перегляд простору станів
Пошук у просторі станів є основою багатьох методів штучного інтелекту, він використовується, наприклад, для вирішення логічних завдань, вибору оптимального ходу, пошуку найкоротшого шляху або планування дій робота.
Простір станів завдання складається зі станів (можливих конфігурацій завдання) і дій (переходів між станами). Один із станів є початковим і принаймні один стан є цільовим. Переходи можуть мати пов’язану ціну.
Простір станів як граф
Простір станів можна представити значним орієнтованим графом, вершини якого відповідають станам, а ребра — діям. Граф простору станів занадто великий для більшості практичних завдань, щоб побудувати його повністю у пам’яті, але деякі алгоритми пошуку поступово створюють частину цього графа.
План – це будь-яка послідовність дій. Рішення завдання – це такий план, який переводить нас із початкового стану до цільового. Оптимальне рішення – це рішення, яке має найменшу вартість. (Ціна плану найчастіше є сумою цін окремих переходів.)
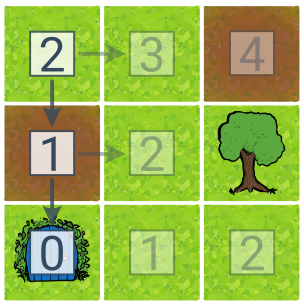
Приклад простору станів (ельф на сітці)
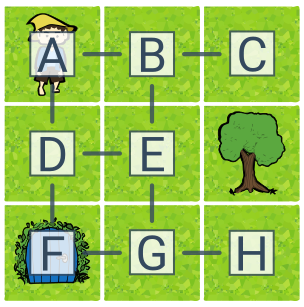
Завдання – завести ельфа у будинок. Простір станів завдання має 8 станів (A–H) і 4 дії (вліво, вправо, вниз, вгору). Початковий стан — А, цільовий — F. Оптимальним рішенням завдання є, наприклад, план вниз—вниз. Прикладом рішення, яке не є оптимальним, є праворуч—вниз—ліворуч.
Спроба всіх варіантів
Найпростішим алгоритмом, який завжди знаходить рішення (якщо воно існує), є згенерувати та перевірити. Цей алгоритм генерує всі можливі плани та перевіряє, чи є вони вирішенням проблеми. Отже, це використання грубої сили — методу розробки алгоритму, заснованого на спробі всіх можливостей. Основним недоліком грубої сили є її трудомісткість. Кількість можливих планів експоненціально зростає з довжиною плану.
Скільки існує різних планів?
Якщо у нас 4 різні дії (P – вправо, D – вниз, L – вліво, H – вгору), то є 4 плани довжини 1, але вже 4^2 плани довжини 2 (PP, PD, PL, PH, DP, DD, DL, DH, LP, LD, LL, LH, HP, HD, HL, HH), плани 4^3 довжиною 3, плани 4^4 довжиною 4 тощо.
Загалом існує k^n планів довжини n з k діями. Наприклад, для 3 можливих дій є 3^5 = 243 планів з 5 кроків, утричі більше планів з 6 кроків, 3^6 = 729, а плани з 20 кроків становлять 3^{20 }, що становить кілька мільярдів.
Дерево пошуку
Однак багато планів можуть бути взагалі нездійсненними, або вони неодноразово повертаються до того самого стану. Тому більш вигідно безперервно тестувати плани після кожної дії – як тільки ми досягаємо тупикової ситуації або раніше дослідженого стану, нам не потрібно досліджувати будь-які інші плани, починаючи з цієї послідовності дій.
Дерево пошуку – це загальна назва такого способу пошуку, коли ми поступово будуємо та оцінюємо плани після кожної дії. Процедуру пошуку плану можна описати за допомогою дерева пошуку, в якому вершини представляють плани (і водночас стан, до якого ми приходимо, виконуючи план), а орієнтовані ребра представляють дії, які розширюють попередній план на один крок. Дерево пошуку фіксує простір станів у міру його поступового виявлення алгоритмом пошуку. Існує кілька варіантів пошуку дерева, які відрізняються планом розширення (тобто який із виявлених станів досліджується наступним).
Пошук у глибину (DFS, англ. Depth First Search) вибирає останній виявлений стан. DFS має добру пам’ять, оскільки запам’ятовує лише плани поточної гілки дерева пошуку.
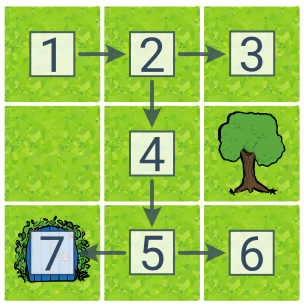
У цьому прикладі ми припускаємо, що DFS намагається виконувати дії за годинниковою стрілкою (праворуч–вниз–ліворуч–вгору). Цифри біля статусів описують порядок появи. Мета була знайдена на кроці 7, а знайдений план складається з 4 кроків (вправо–вниз–вниз–ліворуч).
Пошук у ширину (BFS, англ. Breadth First Search) шукає стани шар за шаром відповідно до кількості дій із початкового стану. Хоча це збільшує складність пам’яті (потрібно запам’ятати більше станів), це краще приводить до найкоротшого рішення.
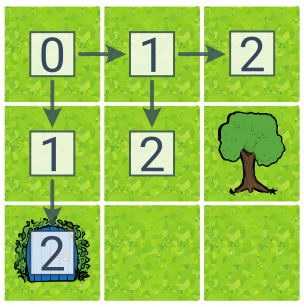
Числа для станів у зразку BFS являють собою відстані від початкового стану, що відповідає порядку обходу «шар за шаром». BFS знайшов оптимальне рішення (вниз–вниз) після дослідження 6 станів.
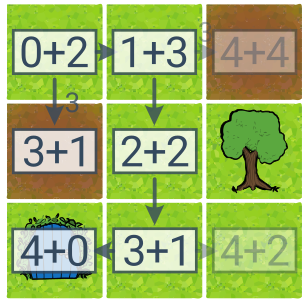
Uniform Cost Search (UCS, англ. Uniform Cost Search) — це варіант BFS, який дозволяє знайти найдешевше рішення, навіть якщо дії мають різні ціни. Ми вибираємо план із найнижчою ціною для розширення.
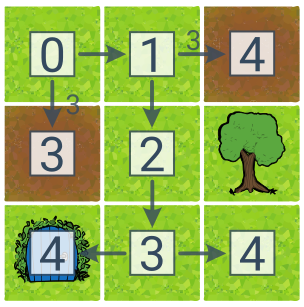
Для демонстрації UCS ми додали два коричневих болота з утричі більшою вартістю переходів на карту. Цифри у квадратах тут відображають вартість плану. У цьому випадку найдешевшим рішенням (з вартістю 4) є праворуч–вниз–вниз–ліворуч, і UCS знаходить його. (BFS поверне рішення вниз–вниз із вартістю 6).
Алгоритм дерева пошуку
Під час використання дерева пошуку ми підтримуємо набір станів, які хочемо дослідити у майбутньому, так званий край. На кожному кроці ми видаляємо один стан із краю та розміщуємо його наступників на краю (тобто стани, які можна досягти з видаленого стану однією дією). Загальна схема пошуку дерева така:
- Поставте початковий стан на край.
- Повторюйте наступні дії, доки не знайдете ціль.
- Видаліть один стан з краю. Якщо це ціль, закінчуйте пошук.
- В іншому випадку розгорніть край, тобто включіть у рішення його наступників.
- Якщо край порожній, шляху до пункту призначення немає.
Згадані варіанти дерева пошуку відрізняються тим, яку стратегію вони використовують для вибору стану з краю (крок 3), тобто як вони реалізують край. Пошук у глибину (DFS) використовує стек (ми беремо останній вставлений стан), пошук у ширину (BFS) — чергу (ми беремо найраніший вставлений стан), а пошук на основі вартості (UCS) — пріоритетну чергу (ми беремо стан із найнижчою ціною найдешевшого плану, що веде до цього стану).
Крім того, щоб уникнути повторного дослідження тих самих станів, ми можемо зберегти набір уже досліджених станів і не розширювати їх знову. Це розширення іноді називають загальним пошуком на графі, щоб відрізнити його від пошуку по дереву без перевірки раніше досліджених станів. Недоліком є збільшення вимог до пам’яті.
Інформований пошук
Пошук можна пришвидшити за допомогою евристики, яка забезпечує оцінку відстані до цілі. Така інформація стосується конкретного завдання. Ми називаємо пошук за допомогою евристики інформованим пошуком. (На відміну від цього ми називаємо алгоритми у попередніх розділах «неінформованими»).
Голодний пошук дотримується лише значення евристики та завжди вибирає дію, яка наближає нас до мети. Якщо є ризик тупикових ситуацій, необхідно поєднати голодний підхід з деревом пошуку (так зване голодне дерево пошуку) – наступним станом вибираємо той, у якого за евристикою найнижча цінова оцінка. Голодний пошук дуже швидкий, але не гарантує знаходження оптимального рішення.
У цьому прикладі голодного дерева пошуку числа для станів відповідають евристичній оцінці вартості до місця призначення. Евристика — це відстань від цілі, яка розраховується як сума відхилень стовпців і рядків. Алгоритм знайшов шлях до місця призначення за два кроки, але це не найдешевший маршрут.
A* пошук („A star“) поєднує пошук на основі вартості (UCS) з евристикою. Це пошук по дереву, де в ролі наступного стану ми обираємо стан, який має найменшу суму ціни на даний момент і евристичну оцінку ціни, що залишилася до цілі. Якщо евристика оптимістична (забезпечує нижчу оцінку справжньої ціни), тоді A* досягне оптимального рішення і знайде його тим швидше, чим ближче евристика надає оцінки справжньої ціни.
Сума станів описує пріоритет для A*: [поточна ціна] + [орієнтовна ціна, що залишилася]. A* знайшов оптимальне рішення, досліджуючи менше штатів, ніж UCS (6 замість 8).
ВгоруВиконання умов
Багато завдань ШІ можна сформулювати як виконання умов. Завдання виконання умов задається набором змінних, їх доменами (можливими значеннями) і набором умов для комбінацій значень змінних. Оцінка (присвоєння значень деяким змінним) є рішенням проблеми, якщо воно повне (присвоює значення всім змінним) і узгоджене (не порушує жодної умови). Іноді також вказується цільова функція, яка визначає значення рішення, яке ми хочемо оптимізувати.
Галузь інформатики, яка займається цими завданнями, називається програмуванням з обмеженнями. Виконання умов є суттю багатьох логічних задач (як-от, задача про 8 ферзів, задача Ейнштейна, алгеброграма). На Знаємо це ви можете спробувати судоку, паркани і бінарні кросворди. Практичне застосування цих знань – це компіляція конфігурацій продукту, які відповідають заданим обмеженням, або створення розкладів (шкільних розкладів, маршрутів транспорту, виробничої логістики, сітки турнірних матчів).
Задача про 8 ферзів
Завдання розставити 8 ферзів на шахівниці так, щоб жоден з них не загрожував жодному іншому. (Ферзя можна пересувати на будь-яку кількість квадратів по горизонталі, вертикалі та діагоналі.) Задачу можна узагальнити до «проблеми N ферзів», які ми маємо розмістити на N×N шахівниці.
Задача Ейнштейна
Завдання визначення властивостей кількох об’єктів на основі обмеженої інформації. Найвідоміша версія завдання описує п’ять різних за кольором будинків, що стоять поруч, з різними власниками за національністю, у яких різні улюблені напої, марка сигарет і домашня тварина. При цьому в нас є 15 рядків інформації типу «Англієць живе в червоному будинку» чи «Норвежець живе біля синього будинку».
Алгеброграма
Завдання полягає в тому, щоб замінити літери різними цифрами, щоб виконувалася задана формула. Приклад: SEND + MORE = MONEY.
Розв’язування задач на виконання умов
Після того, як ми змоделювали проблему як задачу на виконання умови, можна використовувати загальні процедури для її вирішення. Наївна перевірка всіх можливих оцінок (згенерувати та перевірити) зазвичай буде надто повільною, оскільки кількість можливих оцінок експоненціально зростає разом із кількістю змінних. Тому зазвичай використовується поступове створення рішення з поширенням обмежень або поступове вдосконалення повної оцінки.
Які проблеми важкі?
Складність задач з обмежувальними умовами залежить від співвідношення кількості обмежень до кількості змінних. Якщо цей коефіцієнт дуже високий або, навпаки, дуже низький, то знайти рішення (або виявити, що його немає) буде легко. Уявіть собі судоку, де заповнені майже всі поля (числа, що залишилися, визначити легко), або навпаки, заповнено лише кілька полів (різних рішень багато).
Покрокова побудова рішення
Цей підхід полягає в систематичному тестуванні можливих оцінок. Однак, на відміну від «генеруй і тестуй», ми оцінюємо окремі змінні поступово і постійно перевіряємо, чи не було порушено якісь умови. Якщо так, ми спробуємо інше значення. Якщо ми вже перепробували всі можливі значення даної змінної, ми повертаємося до попередньої змінної та намагаємося змінити її значення (цих повернень може бути скільки завгодно). Цей алгоритм називається backtracking.
Відповідність умова vs. планування
Завдання виконання умов можна сформулювати як завдання планування, де стани представляють різні оцінки змінних: початковий стан – порожня оцінка, дії відповідають присвоєнню значення одній змінній, а цільовим станом є повна узгоджена оцінка. (Отже, усі рішення знаходяться на однаковій глибині, враховуючи кількість змінних.)
Відмінність від загального завдання планування полягає в тому, що стани і мета мають внутрішню структуру – стан складається зі значень декількох змінних, мета складається з декількох умов. Завдяки цій внутрішній структурі завдання виконання умов можна вирішувати значно ефективніше, ніж за допомогою загальних методів пошук у просторі станів. Так, ми можемо визнати, що знаходимося в тупиковій гілці, коли якась умова не виконується. Друга відмінність полягає в тому, що нас цікавить не план (послідовність дій, що ведуть до мети, наприклад, порядок заповнення сіток судоку), а стан мети (оцінка змінних, як-от, виконане судоку).
Зворотне відстеження (backtracking) — це по суті глибоке сканування (DFS) із ранньою перевіркою на порушення умов. (Друга відмінність полягає в тому, що порядок дій не має значення — отримане рішення однакове, незалежно від того, чи спочатку ми присвоюємо значення змінній A чи B. Тому, коли виконується пошук із поверненням, нам потрібно шукати лише один порядок змінних. )
Евристика для вибору змінної та її значення має значний вплив на швидкість зворотного пошуку. Для вибору змінної використовується принцип ранньої відмови: ми вибираємо змінну, для якої важко знайти значення (наприклад, ту, що має найменший домен). Навпаки, принцип раннього успіху більше підходить для вибору значень, тобто вибору, який, скоріше за все, може бути частиною рішення (як-от, таке значення, яке спричиняє найменшу фільтрацію доменів). Причина протилежних принципів вибору змінних і значень полягає в тому, що ми закінчуємо циклом усіх змінних, але не значень.
Рекурсивний пошук можна значно пришвидшити шляхом поширення обмежень. Після кожного вибору значення ми виконуємо фільтрацію домена, зменшуючи кількість майбутніх значень змінних, які потрібно буде спробувати.
Поширення обмежень
З доменів змінних ми можемо безпечно видалити значення, для яких умова не може бути виконана (немає значень інших змінних в умові, для яких застосовувалася б умова). (Судоку: коли цифра вже десь розміщена, ми можемо викреслити її з доменів усіх полів у тому самому рядку, стовпці та квадраті.) Якщо в домені змінної залишилося лише одне можливе значення, то ми знаємо частину рішення.
Ми можемо неодноразово перевіряти умови, поки не вдасться викреслити деякі значення. У рідких випадках (легке судоку) повне рішення можна отримати шляхом повторної фільтрації, але частіше ми лише спрощуємо завдання, а потім нам потрібно спробувати різні можливі значення (ось чому поширення обмежень зазвичай використовується у поєднанні з пошуком з поверненням).
Ми можемо досягти більш вираженої фільтрації, якщо перевіряємо одночасно виконання кількох умов, а не завжди однієї (але це збільшує обчислювальну складність).
Поступове поліпшення
Альтернативою поступовій побудові рішення є варіант розпочати з повної оцінки (лише випадкової) і поступово покращувати її з невеликими коригуваннями. Таким чином, оцінка є повною, але не послідовною. Поліпшення – це зміна оцінки, яка зменшує кількість порушених умов. Алгоритми поступового вдосконалення можна розділити на дві категорії залежно від того, чи працюють вони з однією оцінкою за раз (локальний пошук) чи з кількома одночасно (пошук сукупності).
Локальний пошук працює з однією оцінкою, яку поступово покращує. Сукупність усіх оцінок, які відрізняються від нинішніх однією зміною, ми називаємо оточенням. Метод найбільшого підйому (алгоритм сходження) вибирає з оточення рейтинг, який приводить до найбільш значного покращення. За допомогою цієї процедури ми швидко досягаємо локального оптимуму, коли всі навколишні умови є гіршими. Однак локальний оптимум може не бути глобальним оптимумом, зокрема він може не бути допустимим рішенням.
Тому необхідно використовувати метаевристики, які вносять елемент випадковості у пошук і, таким чином, дають шанс вийти з локального оптимуму. Прикладом метаевристики є імітований відпал, у якому ми вибираємо випадковим чином із середовища; якщо нова оцінка є покращенням, ми приймаємо її, якщо це не покращення, ми приймаємо її з певною ймовірністю, яка поступово зменшується. Проста метаевристика також полягає у багаторазовому запуску локального пошуку з різних випадкових початкових значень.
У пошуку сукупностей ми покращуємо багато оцінок одночасно. Це дає змогу вибрати найкращу із поточної сукупності та, можливо, поєднати різні оцінки. Прикладом є генетичні алгоритми, створені за принципом еволюції. Оцінки, які продовжуються до наступного покоління, вибираються відповідно до їх якості, об’єднуються («схрещування») і, можливо, дещо змінюються випадковим чином («мутація»). Інші природничі алгоритми, які використовують значну кількість взаємодіючих агентів, що представляють повні оцінки, також належать до цієї категорії. (Наприклад, у «оптимізації мурашиної колонії» кожна мураха має пов’язану оцінку і випромінює феромонний слід різної сили залежно від її якості. Що краща ця оцінка, то ймовірніше, що інші мурахи спробують отримати подібну.)
ВгоруОптимізація
Оптимізація означає пошук найкращого рішення. Ми шукаємо значення оптимізованих змінних, при яких зазначена цільова функція є найвищою (максимум) або найменшою (мінімум). Оптимізація використовується, наприклад, у плануванні виробництва, транспортному розкладі, проєктуванні телекомунікаційних мереж і навчанні моделей у машинному навчанні.
Оптимізаційні задачі
Проблеми максимізації та мінімізації можна розв’язувати за допомогою тих самих методів, оскільки кожна задача максимізації може бути перетворена в задачу мінімізації (і навпаки) інвертуванням цільової функції. Однак різні методи відрізняються тим, чи можна їх використовувати в дискретному чи безперервному просторі (у безперервному просторі змінні можуть набувати довільних дійсних чисел) і чи може проблема містити обмежувальні умови.
Приклади оптимізаційних задач
Проблема з рюкзаком. Виберіть комбінацію предметів, яка поміститься в рюкзак обмеженої місткості, щоб максимізувати загальну вартість.
Проблема продавця. Знайдіть найкоротший маршрут, який проходить через усі вказані міста та повертає до початкової точки.
Планування. Знайдіть оптимальний (найкоротший, найдешевший) розклад діяльності в часі з урахуванням заданих ресурсів і обмежень.
Машинне навчання. Виберіть параметри моделі (наприклад, вагові коефіцієнти нейронної мережі), мінімізуючи помилку прогнозування даних навчання.
Проблема шоколадного печива. Знайдіть найкращий рецепт шоколадного печива.
Систематичний пошук
Найпростіший підхід — спробувати всі варіанти (груба сила). У безперервному просторі можливості нескінченні, але можна систематично пробувати всі комбінації значень із певною роздільною здатністю (пошук у сітці). Цей підхід застосовний лише до дуже невеликих проблем, оскільки кількість можливостей експоненціально зростає з кількістю змінних. Під час розв’язання задачі про рюкзак ми можемо брати або не брати кожен об’єкт, тому існує 2^n можливих комбінацій об’єктів.
Ефективніше призначати значення змінним поступово і постійно оцінювати найкраще можливе значення рішення з заданим частковим призначенням. Коли ця межа гірша за найкраще рішення, знайдене на даний момент, ми можемо пропустити всю гілку та бути впевненими, що ми не пропустили оптимальне рішення. Цей варіант пошуку дерева називається методом **розгалуження та зв’язку*. Щоб вибрати наступний стан для дослідження, можна використати голодний критерій – стан із найкращим граничним значенням (або іншою стратегією перегляду простору станів).
Голодний і випадковий пошук
Систематичний пошук гарантує знаходження глобального оптимуму, але дуже часто надто повільний для практичних завдань. Для прискорення необхідно відмовитися від вимоги оптимального рішення, на щастя, для більшості практичних завдань достатньо рішення, яке є «досить хорошим». Потім для прискорення можна використовувати голод і випадковість.
Голодний пошук вибирає значення для кожної змінної, яке здається найкращим на даний момент, і не повертається до цих рішень. Під час вирішення проблеми з рюкзаком ми могли брати предмети з найвищим співвідношенням ціна/вага один за одним, поки вони не помістяться в рюкзак. Голодний пошук дуже швидкий, але знайдене рішення може бути дуже поганим. Між крайнощами голодного пошуку (випробування одного шляху) і систематичного пошуку дерева (випробування всіх шляхів) існує променевий пошук (випробування фіксованої кількості шляхів). Променевий пошук залишає лише фіксовану кількість найкращих станів на кожному рівні дерева та відкидає інші.
Випадковий пошук перевіряє випадково вибрані рішення (замість усіх можливих). Існують більш складні техніки, які поступово збільшують ймовірність вибору рішень у перспективних областях – вони намагаються збалансувати дослідження недосліджених областей (випадковість) і використання інформації про більш досліджені (голод). Цей компроміс між дослідженням і використанням є загальним принципом, який можна зустріти у багатьох алгоритмах оптимізації.
І голодний пошук, і випадковий також використовуються у методах поступового вдосконалення, які ми розберемо у наступних розділах.
Локальний пошук
Альтернативою поступовому створенню рішення є початок з довільного рішення та поступове покращення його невеликими змінами. Цей підхід називається локальним пошуком. Ми називаємо набір найближчих рішень, які відрізняються від поточного однією зміною, оточенням. (Під час розв’язання задачі про рюкзак до оточення можуть входити, наприклад, ті комбінації, які відрізняються щонайбільше одним доданим і одним вилученим предметом.) Існують різні евристики для вибору наступного рішення з оточення. Алгоритм підйому вибирає деякі поліпшувальні рішення або найкраще рішення з оточення (цей варіант алгоритму підйому називається методом максимального підйому).
Використовуючи ці голодні евристики, ми швидко приходимо до локального оптимуму, тобто рішення, яке є найкращим у своєму оточенні, але не обов’язково має бути глобальним оптимумом. Шанси знайти глобальний оптимум можна збільшити за допомогою випадковості. Імітація відпалу випадково вибирає з оточення: якщо нове рішення є поліпшенням, то ми його приймаємо, якщо це не поліпшення, то приймаємо його з певною імовірністю, яка поступово зменшується.
Еквівалентом локального пошуку в безперервному просторі є градієнтний спуск. У безперервному просторі часто можна обчислити напрямок, у якому цільова функція спадає або зростає найшвидше (так званий градієнт), тоді немає потреби тестувати різні рішення поблизу. Градієнтний спуск зазвичай використовується у машинному навчанні, наприклад, для оптимізації ваг нейронної мережі.
Пошук сукупностей
Під час пошуку сукупностей ми вдосконалюємо багато рішень одночасно. Це дає змогу вибрати найкраще рішення з поточної сукупності та, можливо, комбінувати різні рішення. Прикладом є генетичні алгоритми, створені за принципом еволюції. Розв’язки, що продовжують наступне покоління, вибираються відповідно до їх якості (значення цільової функції), комбінуються («схрещування») і, при необхідності, злегка випадково змінюються («мутація»).
Ця категорія також включає алгоритми ройового інтелекту, натхненні груповою поведінкою виду (зазвичай під час пошуку їжі). Ці алгоритми використовують велику кількість простих агентів, що представляють різні рішення, які опосередковано взаємодіють один з одним через спільну пам’ять. Наприклад, в оптимізації колонії мурашок кожна мураха має пов’язане рішення та випромінює феромонний слід уздовж свого маршруту, який тим сильніший, чим краще рішення. Усі сліди феромонів разом утворюють спільну пам’ять, за якою потім йдуть інші мурахи (вони віддають перевагу шляхами з більш вираженим слідом феромонів, які зарекомендували себе в минулому).
Вгору